使用AI语音识别为视频生成字幕
从PC 13.3版本开始,弹弹play支持通过AI语音识别技术,为视频生成字幕文件。
功能特点
- 识别率高,普通(Small)模型即可达到>90%的准确率
- 由 OpenAI Whisper 驱动,识别将完全在本地处理,无需联网
- 集成在弹弹play播放器中,即开即用,不需要安装 Python 等其他软件
- 使用 GPU 加速识别,支持 A/N/I 显卡
- UI方便简洁,一看即会
使用方法
1. 进入 "AI语音识别" 界面
您可以通过多种方式进入“AI语音识别”界面,例如:
在播放界面中,右键弹出菜单,选择“弹弹play AI - AI语音识别”即可对当前文件进行语音识别
视频播放时,在播放器的【调整】边栏中,点击【AI语音识别】按钮:
播放列表界面中,选中多个视频,点击工具栏上的【AI语音识别】按钮:
媒体库中,右键点击视频,在出现的菜单中选择【AI语音识别】:
2. 准备必要文件
在开始前,您需要提前下载两个必要的文件,将其放入指定的文件夹中:
FFmpeg(弹弹play已自带):约110MB,用来处理音频。 您也可以选择下载最新版的 ffmpeg.exe 手动解压。如果您下载的是zip压缩包,请手动解压其中的 exe 文件到指定文件夹。
AI模型文件:用来识别音频内容。 请根据需求选择要使用的模型。我们推荐使用普通(Small)或中等(Medium)模型来识别动画,可以在识别率、识别速度中取得不错的平衡。如果对效果不满意可以再换成别的模型尝试。 模型文件需要自行下载。点击“去下载”链接打开浏览器下载文件,下载到的 .bin 文件请放到指定的文件夹中。
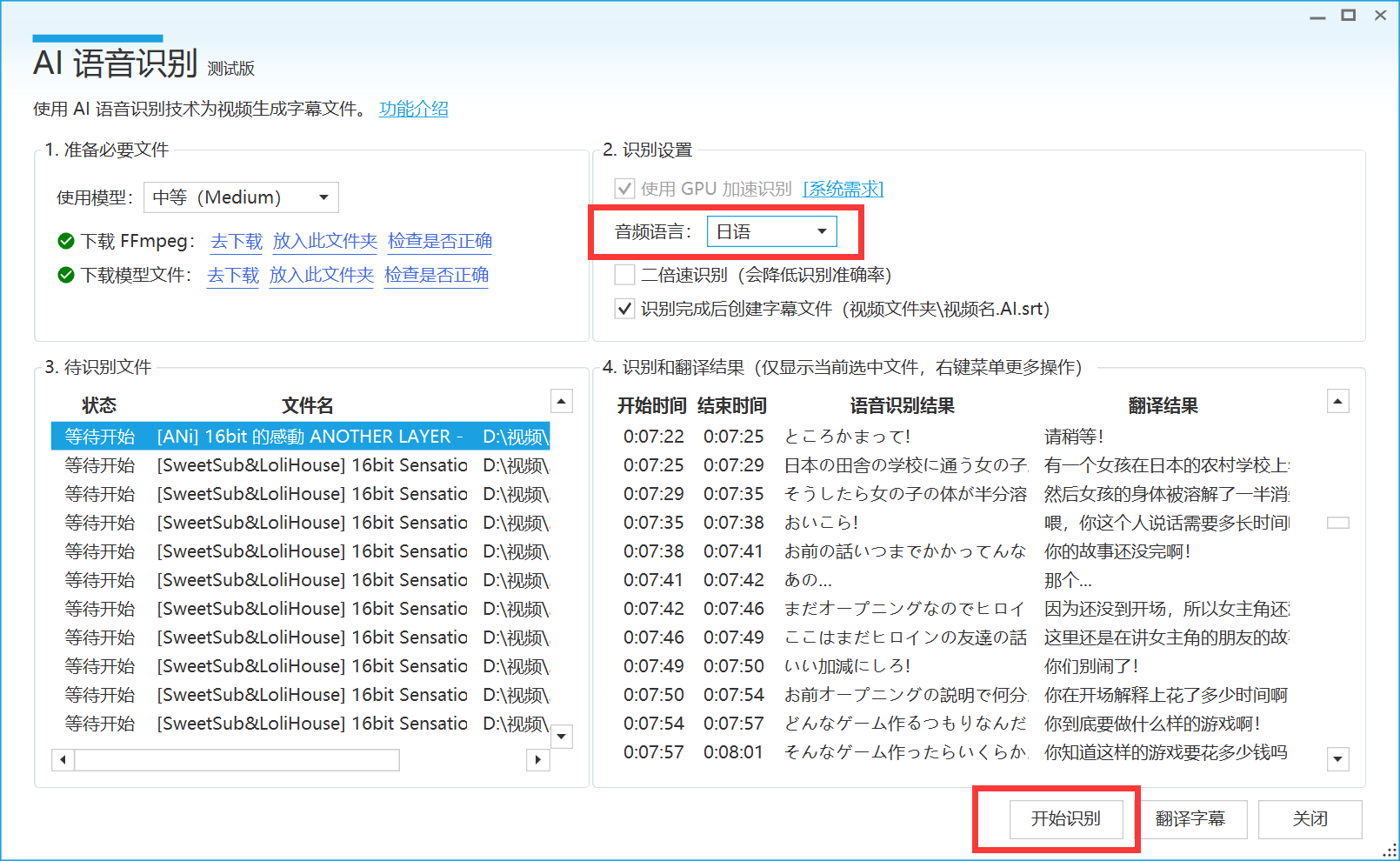
3. 选择语言并开始识别
点击最下方的【开始识别】按钮启动后台语音识别。弹弹play将首先处理视频中的音频轨道,然后加载 AI 模型,之后开始识别其中的内容。
识别出的内容将不断更新在下方列表中,您可以随时查看。点击【中断】按钮可以提前结束识别任务。
转换速度将由您的 GPU 速度、模型大小共同决定。举例来说,在使用 NVIDIA GTX 2060 的笔记本电脑上,选择普通(Small)模型识别一个时长24分钟的TV动画视频,将花费约 2~4 分钟时间。音频中的无人声/环境音部分可能会降低识别速度。
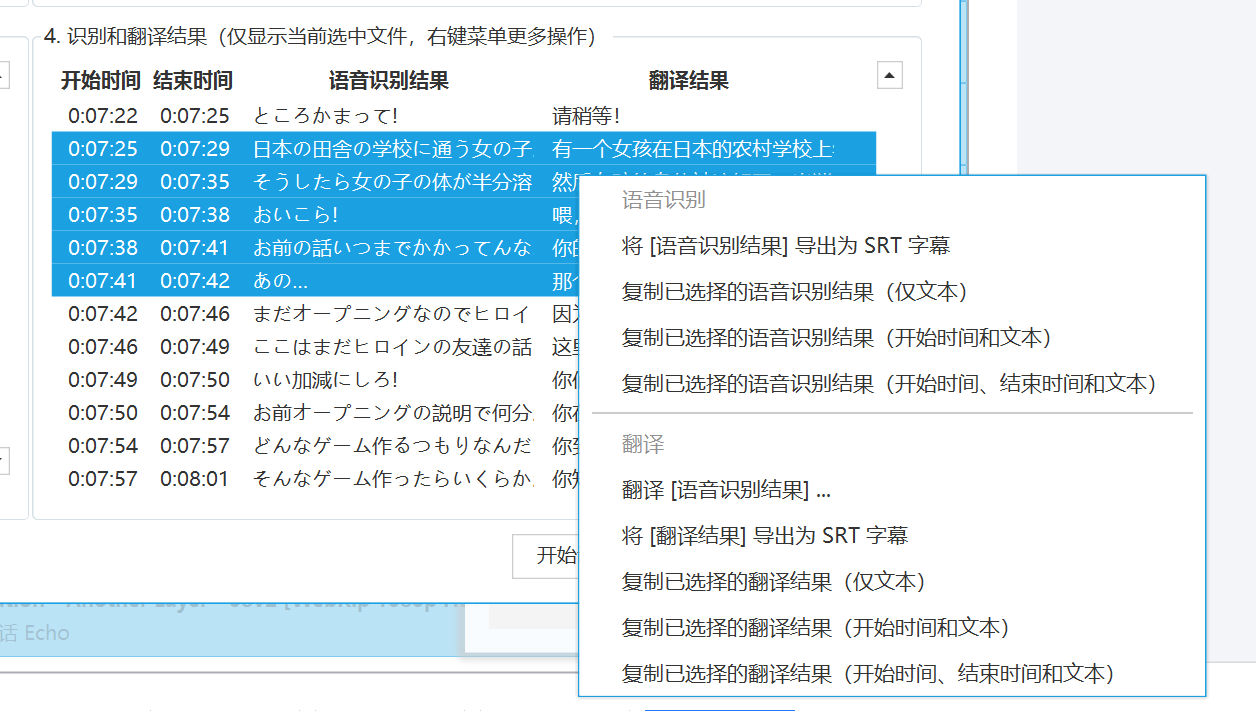
4. 生成字幕或导出数据
转换完成后,将根据设置(如果选择了生成字幕选项),自动生成 SRT 格式的字幕文件。
您也可以在识别结果区域右键点击,进行更多高级操作:
- 如果您正在批量处理视频,识别结果区域将显示选中文件的识别结果。
关于 GPU 加速识别
弹弹play的 AI语音识别 功能强制使用 GPU 加速识别(此选项默认开启,无法关闭),相比旧版本的 CPU 识别,会获得至少 10 倍的速度提升。但开启 GPU 识别功能,对软硬件都有一些要求:
- 需要一个支持 DirectX 11 的显卡,不是非常旧的显卡一般都可以
- 操作系统至少为 Windows 10 版本 1803 (10.0.17134.0)
- 系统中有 VC++ 2022 x64 运行库。如果出现了相关的报错,可以 点击这里 下载安装
已知问题
- 如需处理音频文件,请在播放器界面右键打开菜单,选择“弹弹play AI - AI语音识别”菜单项,此处支持选择音频格式的文件。
- 如果系统中只有核芯显卡,没有独立显卡,可能无法使用 GPU 加速识别,此时会自动降级为 CPU 识别模式,识别速度会较慢。
- UWP 版本由于商店限制,无法运行语音识别功能。
- 目前不支持 Whisper 最新的 Large v3 版本的模型文件,如需使用 大型(Large)模型,请下载文件名中带“v2”的版本。下载后仍将其命名为指定的文件名,如 ggml-large.bin 。